Resource Pools have been part of VMware vSphere and Virtual Infrastructure for as long as I can imagine. The same can be said regarding the mishandling of Resource Pools and that is most likely because they are frequently misunderstood. More often than not I see Resource Pools being used to categorize or organize VM workloads (i.e. application type, OS type, etc.) and use the Resource Pool more like a folder. What is the potential impact of doing this? Performance problems.
Before we get into the ‘how’ lets dive a little into the reason’s ‘why’ and ‘when’ to use them. First and foremost your vSphere cluster has to have DRS enabled which is entirely dependent on which version of vSphere you are licensed. DRS is available in Enterprise Plus and Platinum editions and not available in Standard. If you’re licensed for Standard then you do not have to worry about Resource Pools.
A couple other things you need to understand before getting deeper in the weeds is understand the use of shares and reservations. Very easy to understand and differentiate between the two and we will keep it short and sweet.
- Shares are a way of setting a priority for VMs; this makes sure the VM has access to CPU and memory resources before another VM can make a request. If you have a vSphere cluster with a mixed set of workloads (ex: prod, dev and test) then logically you would want the production workloads to have higher share values. One thing you want to remember about shares is they only become a factor when resource contention is present. If your cluster is properly sized you should rarely run into contention.
- Reservations are used to guarantee resources are available at all times. Using reservations is ideal for your mission critical workloads where you want and need to guarantee performance. However, the downside to this is those resources are not available for other VMs to use. So if you reserve 8GB of memory for a VM then that 8GB of memory is locked onto the VM.
Now let’s get into a little bit of ‘Resource Pools 101’ for a moment. If you had someone who was new to vSphere come up to you and ask ‘what is a resource pool?’ what would your answer be?
Answer: They are simply a logical abstraction of resources which provide a flexible means of managing resources; and they can be grouped hierarchically. They are used to partition available CPU and memory resources.
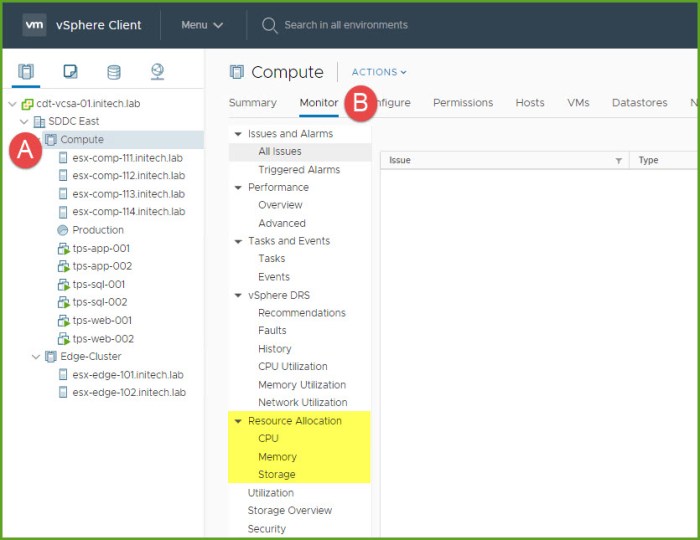
By default there is a root resource pool in a DRS enabled cluster (or standalone host) which is nothing more than the total aggregate of CPU and memory resources available. You can find the total of resources in the root pool by selecting the cluster in the vSphere Client, select Monitor and then choose Resource Allocation; and beneath this option you will see CPU, memory and storage (see below). Choose one of the three options and you will see ‘Cluster Total Capacity’ for each resource at the root level.
Now what about environments where there are dedicated clusters for specific uses? I have come across many instances where customers have clusters (sometimes storage) dedicated for things like Oracle, management and application specific workloads. If your environment is like this then there is really no reason to introduce resource pools because the clusters are the resource pool. It’s just one big pool and introducing additional pools would also introduce additional complexity and increase performance risk due to improper management. So unless there is a justifiable reason, don’t do it.
My recommendation would be to get into the habit of using VM Folders as well as using Tags and not use them only for dedicated clusters but also clusters where you may be running a mixed set of workloads. I’m a big fan of tags because they are easy to use and they are searchable in the vSphere Client plus if you get more into the software defined world, such as NSX, you can leverage for DFW rules. End rant and moving on!
Resource Pool Scenario
Now we will get into Resource Pools a little deeper with a scenario. First make the assumption where the resource pools are deployed and used like ‘folders’ to organize resources and set with the default High, Normal and Low share settings w/ no reservations or limits. What would the potential impact look like?
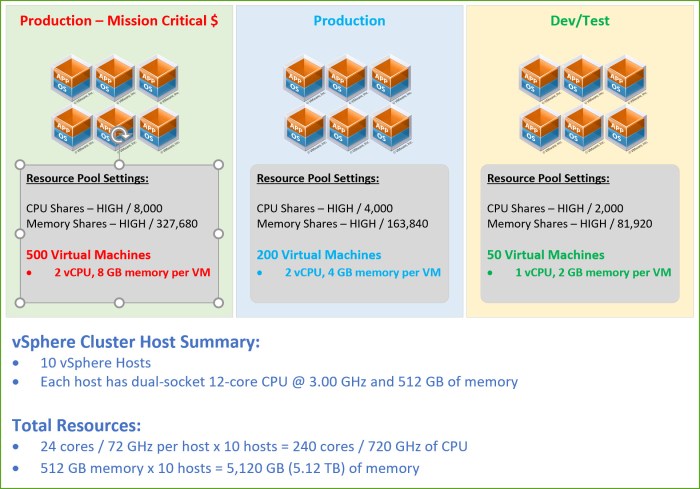
NOTE: I made a mistake with graphic above. The pools are High, Normal and Low as I stated. The graphic indicates High for all 3 pools which is wrong. I’ll fix this graphic later (08/15/19).
The cluster above has 10 ESXi hosts which brings the root pool to a total of 240 CPU cores (720 GHz) and 5,120GB (5.12 TB) of memory (a more thorough breakdown available in graphic above).
This environment has three (3) different types of virtual machine workloads each with a specific virtual hardware configuration. The applications that this organization uses are more memory intensive than CPU.
- Production – Mission Critical (500 VMs)2 vCPU, 8 GB memory per VM
- Total of 1,000 vCPUs and 4,000 GB of memory
- Production (200 VMs)2 vCPU, 4 GB memory per VM
- Total of 400 vCPUs and 800 GB of memory
- Dev/Test (50 VMs)1 vCPU, 2 GB memory per VM
- Total of 50 vCPUs and 100 GB of memory
- Totals for the entire cluster750 virtual machines
- 1,450 vCPU’s (~6:1 vCPU-to-core ratio)
- 4,900 GB of memory
The cluster can “run hot” at times but the cluster is sized to run the necessary workloads and there is very little growth year-over-year.
Suddenly disaster strikes and the cluster suffers a single host outage and the amount of CPU and memory resources drops significantly. Complaints are flowing into the call center. All workload associated with both tiers of production are running extremely slow and impacting business. Why is performance being impacted?
The problem we are running into here is the Dev/Test VM’s actually have more shares on a per-VM basis than the VM’s in what was assumed to be the higher priority pools. The assumption made using the default ‘High, Normal and Low’ share values on the resource pools would ensure CPU and memory resources would be readily available to the workloads. This ended up being the problem.
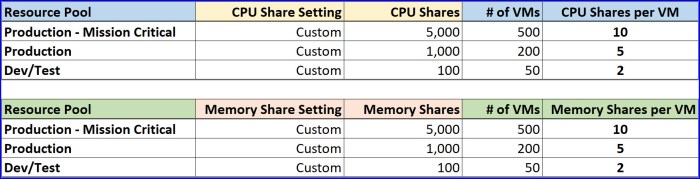
Let’s look at the entitlements for the VM’s in each Resource Pool in the table below to understand a little more.

The Production – Mission Critical VMs are suffering the most during during the outage; contention is high because they actually have the lower share value on a per-VM basis. The Dev/Test VM’s have the highest entitlement to CPU and memory resources because they have a higher share value. So those VMs are getting 1st come, 1st serve access to CPU and memory resources before the other workloads. This is bad.
The Solution
The problem in the scenario can be quickly fixed by customizing the share value on each resource pool to ensure Mission Critical gets more shares of CPU and memory than the other two pools. The one thing that tends to get overlooked by virtual administrators is the share value is actually an ‘arbitrary’ value. There is also an assumption made that these share values are automatically applied onto each VM meaning if my pool has 8000 shares then each VM has 8000 shares of CPU or memory and that is entirely false. Think of the share value as a ‘total pie size’ and each VM gets a portion of that pie; simply divide the # of shares by the # of VMs and that is result is the entitlement on a per-VM basis.
If you have a very active environment where VMs are constantly being deployed and removed then the entitlement values will fluctuate up and down. My recommendation would be for admins to modify these share values as VMs are added or removed from the Resource Pools. Start using the ‘Custom’ option versus one of the default share values of High, Normal or Low. Custom will give you more flexibility in this situation.
Here’s an example of a Custom Resource Pool and how I would manage it. I like to use round numbers because you can do some quick easy math in your head when calculating entitlements. I’ll stick with the scenario above and demonstrate how the customized shares would have ‘maintained balance’ between the different workloads.
Remember the share value is an arbitrary number so you can select pretty much any number you want provided it aligns with the math and desired outcome. The easiest way is to create the equation in the reverse and ask yourself the following question…
How many shares do I want on a per-VM basis for each resource pool?
So here I would decide that each ‘Production – Mission Critical’ VM should have 10 shares, each ‘Production’ VM should have 5 shares and then each Dev/Test VM should have 2 shares. Take that number and multiply it by the # of VMs in each pool and the result will be you custom share value.
Now let’s test this equation out by assuming the # of VMs have changed for each pool. The goal here is to ensure the share values (entitlements) on a per VM basis remain the same. Let’s assume the following happens in the cluster:
- Production – Mission Critical goes from 500 VMs down to 472 VMs.
- Production goes from 200 VMs up to 248 VMs.
- Dev/Test doubles in size from 50 to 100.
Reference the table below and how the custom share values need to be adjusted to ensure the entitlements remain the same and maintain balance between the pools.
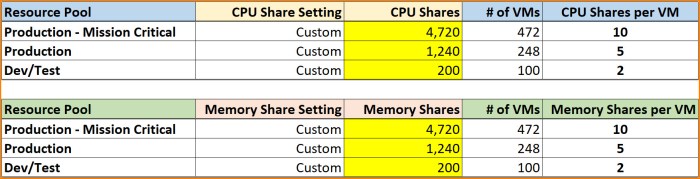
- Production – Mission Critical: 10 Shares * 472 VMs = 4,720 Shares (CPU & memory)
- Production: 5 Shares * 248 VMs = 1,240 Shares (CPU & memory)
- Dev/Test: 2 Shares * 100 VMs = 200 Shares (CPU & memory)
The balance between the pools remains despite the slight fluctuation of VMs. If contention were to raise its ugly head again the Production – Mission Critical VMs would have the highest priority to resources ahead of Production and Dev/Test.
What If Scenario’s
Let’s take the scenario above and instead of applying the ‘High, Normal and Low’ settings on each Resource Pool we will assume the admin who created them used the default Normal setting on every pool. Each pool is configured with the exact same number of shares for CPU and memory. This is very common in situations where Resource Pools are used like a folder and therefore negatively impact performance. Let’s examine what would have happened in this scenario and what the impact could look like?
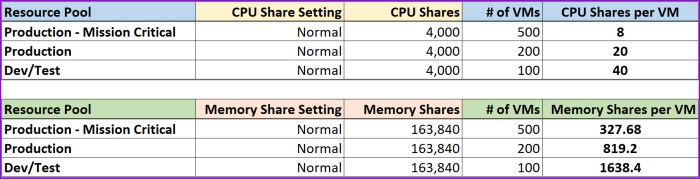
Here we see it again, the pool with the least # of resources “WINS” during periods of contention. So again we have another very common mistake with using Resource Pools and the risk it poses for the environment.
Next let’s look at a couple situation’s where an admin would ‘get lucky’ by using the default settings and not create a situation where the most important workloads still end up in a good spot. First let’s assume there is an equal # of virtual machines in each pool. In this situation the top tier systems have highest priority to resources during contention.
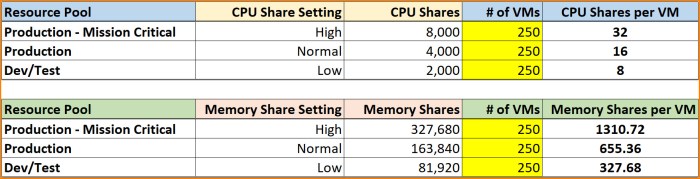
Next let’s flip the number of VMs around a bit from the original scenario and see what would happen if Dev/Test has the highest # of VMs deployed and Production – Mission Critical had the least # of VMs deployed.
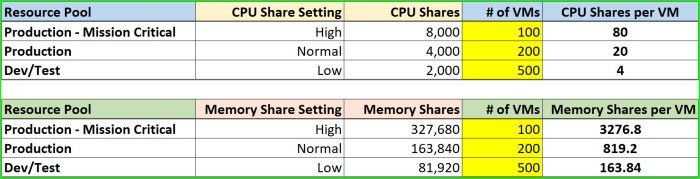
In this case the obvious answer is ‘Production – Mission Critical’ would be in a good spot should contention exist…highest # of shares and lowest # of VMs. These VMs are only in a good spot because they are outnumbered by the lower priority VMs.
Conclusion
Hopefully this helps clear up any confusion you may have been having when it comes to managing resource pools. There is some administrative overhead associated with using them so use them with caution. Improper use will introduce risk and likely lead to performance issues at some point. The scenario I covered above didn’t experience contention until a host outage occurred. That isn’t the only time contention can happen. I’ve come across multiple clusters over the years where over-subscription of CPU and memory resources was present and the admins were completely unaware because they didn’t track the usage or what was provisioned. Over-provisioning of resources increases the likelihood of contention in any environment, not just environments with a mixed set of workloads. It is very important to carefully plan and size the environment for the workloads needed. Know where the constraints and limitations are otherwise you are operating blindly and I promise you will eventually run into performance issues. It’s only a matter of time.
Leverage tools such as RV TOOLS for tracking your inventory but most importantly look into using VMware vRealize Operations to help you not only right-size the environment but reclaim wasted resources created by over-provisioning. Over-provisioning of resources impacts cost and reclaiming those unused resources will ultimately save your organization money and depending on the size of the environment this could be savings in the millions. Yes millions!
Effective and efficient operations means you will maximize your investment!
Recommendation Summary
- Use Resource Pools only when necessary, work great in environments with mixed workloads but your 1st resort should be using CPU/Memory ‘reservations’ on the mission/business critical VMs first and then observe the performance and make adjustments as needed. Avoid introducing additional complexity with Resource Pools if reservations provide the expected performance levels. One thing you want to be cautious about with using reservations is you must revisit your vSphere HA Admission Control policy/strategy; reservations will have an impact on slot size if the default HA Admission Control policy is being used (# of host failures to tolerate). In vSphere 6.0 and prior this was a default setting. In vSphere 6.5/6.7 the ‘Slot Policy (powered-on VMs) is the option you want to be careful using.
- Use VM Folders and Tags if you are looking to organize VMs in the inventory. Much more effective and Tags are a very useful tool when they are planned and carefully implemented. Clean organization will lead to better operations.
- Leverage tools to help you right-size VMs and reclaim wasted resources. vRealize Operations (vROps) is a great tool that is perfect for every vSphere environment and an administrators best friend. If you are new to vROps or have not worked with vROps in a long time then please check out the free Hands On Labs today!
Hope you enjoyed this post! Little bit of a ‘101 level’ blog article but really wanted to provide my own insight on this topic as I have found Resource Pool misuse quite a bit lately.

Reblogged this on Nguoidentubinhduong.
LikeLike