I have come across a few instances recently where a couple customers want to take advantage of VMware VSAN and NSX together. One of them already had VSAN running in their environment and now want to take advantage of NSX. The second is literally doing a complete server/storage refresh and want a brand new deployment of VSAN and NSX all together. Both customers are utilizing VSAN Ready Nodes in their environment.
Some of you may actually be in the same situation as these people and are likely asking the some of the same questions…
- How many network connections do I need for each of my ESXi hosts?
- What implication will this have on my vSphere clusters?
- How many hosts will I need?
- Why do I need to separate NSX Edge & Management?
- How do I factor in availability/redundancy?
All great questions. The one thing about tackling this type of solution is the end result will nearly be conceptually and logically the same. So what I am going to do here is focus on how I will go about designing a solution and then I will also cover some of the why…thus providing justification for designing a VMware SDDC solution that utilizes VSAN and NSX.
The POC Phase
First and foremost, always start with some type of POC phase if you can. Two constraints that may prevent this may be customer timeline or budget. If a customer has both the time and budget to perform a POC then by all means do it. Take advantage of this time to get them familiar with the new technology and do some rigorous testing. A VSAN POC for my one customer will not be necessary because they already have it and are very familiar with it. So I will solely focus on NSX with them. On the other hand a POC for VSAN and NSX will be very beneficial to my other customer who is new to both solutions.
Fast forward and lets assume all of the prerequisites for VSAN and NSX are met and begin building the POC. How would I proceed with designing the POC? First I get myself into the mindset of keeping it simple. My goal for the POC is straightforward…enable the customer to see the benefits of using both solutions separately and collectively. I would underline the fact that the number of physical nodes at this point is irrelevant and want to simply focus on functionality and familiarizing them with the technology. This is also a great time to conduct some knowledge transfer. That way you aren’t conducting a knowledge transfer with them on the live production equipment. Get them comfortable with the solutions long before they are in production.
If you are in a similar situation as my second customer then a POC is going to be very easy. They plan on purchasing all new gear for VSAN and NSX. The environment will be built parallel to their existing production environment. Therefore we will conduct our testing on the new infrastructure prior to migrating anything from the legacy infrastructure. So the new environment is more than ideal…it’s PERFECT for performing various testing procedures including any knowledge transfer.
- What if they don’t have the timeline or budget for a POC?
- What if they don’t have spare gear to conduct a POC?
In this case the project will likely use existing gear. This happens quite often and that is perfectly okay. You simply want to highlight the risks moving forward associated with an in place upgrade/migration. The most important thing here will be providing a list of methods to mitigate risk. This is likely where you will begin developing numerous procedures.
If the biggest question mark is simply knowledge transfer and/or education…you simply don’t want to conduct that on production gear. Simply direct them to one of two places.
- First make them aware of VMware training options. Hopefully they have some training credits that they can use.
- If not, then direct them to some VMware Hands-On Labs! Get familiar with the product there and beat those environments up as much as they want. Go crazy!
Next, how would my ideal POC look like at a minimum? Assuming all of the hardware requirements have been met for both VSAN and NSX I would start with a 4-node cluster. Then begin installing everything in the following order (at a high-level):
- Install and configure ESXi on all four (4) ESXi hosts.
- Configure VSAN on one node.
(Yes this is possible and can be accomplished. Google search ‘VSAN Bootstrap’ and see what comes up.) - Deploy a VCSA appliance for the PSC and vCenter Server.
(Embedded PSC if you want but I would deploy this exactly how I would intend on deploying it in production so the customer knows what to expect.) - Add my three (3) remaining nodes into my single VSAN cluster to complete a four (4) node cluster design.
- Finalize the VSAN cluster configuration.
- Enable and configure vSphere HA/DRS (if necessary).
- Migrate everything to a vSphere Distributed Switch.
- Finalize any additional ESXi host VMkernel configurations (i.e. vMotion).
- Create the required distributed port groups.
- Review the MTU requirements for VSAN & NSX.
- Deploy NSX Manager and proceed with configuring some basics for NSX including:
- NSX Manager integration with PSC/vCenter Server.
- Deploy NSX Controllers.
- Prepare the hosts/clusters.
- Create transport zone.
- Create some logical switches, edge routers and DLRs.
SUMMARY: I have four (4) physical servers running ESXi. Each host has ample CPU & memory as well as local SSDs that provide cache and capacity for my VSAN datastore. Remember you only need one (1) SSD for cache and one (1) SSD for capacity. I have at least two (2) 10GbE network connections per host. I can then utilize NOIC on my vDS to manage bandwidth consumption. I have separate VLANs for management, vMotion, VSAN and the NSX VTEPs. Do not put all of them on the same VLAN / network segment.
Will the configuration enable them to test a VSAN policy for Erasure Coding in the POC? The answer is yes but only for a single node failure. If there is a requirement that must test and validate a 2-node failure for Erasure Coding for the future production environment then the POC environment must contain at least six (6) nodes. So keep that in mind if you come across a similar situation.

NOTE: I found a great post recently for “VSAN Bootstrap” for VSAN 6.6. The article I found was written by Jase McCarty. Great write up and I plan on attempting this procedure in the very near future.
Bootstrap the VCSA onto vSAN 6.6 with Easy Install
Designing for a Medium Size Deployment
So we completed the POC and are ready to move onto designing everything for production. NSX and VSAN are very flexible (elastic); both can adapt to various sizes all contingent upon workload requirements. First thing you want to be aware of is the minimums and maximums for everything…vSphere, VSAN and NSX. You don’t have to memorize them as there are too many but you should know where to reference them when needed.
Here are a few reference links that I highly recommend. Always remember to read the release notes, reference the VMware Product Interoperability Matrix and the HCL.
vSphere 6.5 Configuration Maximums (PDF) – vSAN can be found on page 25 of this guide.
VMware NSX-v Configuration Maximums by Martijn Smit
VMware Product Interoperability Matrices
VSAN 6.2 Release Notes
VSAN 6.5 Release Notes
VSAN 6.6 Release Notes
NSX 6.2.0 Release Notes
NSX 6.3.0 Release Notes
One of the primary goals when designing a production NSX implementation is separating management and the NSX control plane from the compute clusters. Management/Edge clusters will never contain any production VM workloads. It is strictly utilized for running anything pertaining to managing or supporting the vSphere & NSX infrastructure. You will deploy VM management appliances here such as (but not limited to)…
- Platform Services Controller (PSC)
- vCenter Server
- NSX Manager
- NSX Controllers (3)
- Cloud Management Platforms (vRA, VIO, etc.)
- NSX Control VMs for ESG and DLRs
- vRealize Operations, Log Insight and/or vRealize Network Insight (vRNI)
You could place many other infrastructure related VMs in this cluster as well such as your DNS/DHCP servers, domain controllers and so on.
The first customer that I mentioned above will be deploying a mid-sized environment. There will be two (2) separate vSphere clusters; each cluster running its own separate VSAN. The compute cluster will remain in place initially and then be upgraded from 6.0 to 6.5. One of their main goals is to take advantage of Erasure Coding for the space savings. Eventually they want to protect the compute environment for up to two (2) node failures. So the short-term plan is to get things running on a four (4) node cluster first; then expand to six (6) nodes and create a VSAN SPBM policy for a two-node failure later.
They have procured new server hardware for the new management/edge cluster and will utilize VSAN on that cluster as well. They love it and don’t want to use anything else. The two clusters will nearly mirror of one another initially with one exception being the compute cluster will have more capacity than the management/edge cluster.

Could I have put everything in single eight (8) node vSphere/VSAN cluster? Sure and if I were to do this would require some complex DRS anti-affinity rules to separate specific VM workloads because I do not want the NSX control VMs and compute workloads running on the same host simultaneously. Just more overhead and aggravation.
The 8-node cluster (with regards to VSAN) would require all of the workloads to access the same storage. Specifically workloads with different I/O and capacity requirements. Can I do this? Sure. But then I need to get very creative with my VSAN storage policies. Again more overhead and complexity.
In some cases logically and physically separating the workloads will minimize complexity, increase flexibility and enable you to troubleshoot more efficiently. Each cluster can scale independently as needed. My recommendation would be to create separate clusters!
I like to stick to two of my favorite quotes when designing an environment like this…
“KISS method….keep it simple stupid!”
“Just because you can doesn’t mean you should!”
Next…what happens when it comes time to scale? Scaling will be fairly easy. Let’s start with NSX which will continue to run normally as new ESXi nodes are added to the environment. The new nodes will require NSX host preparation just as the other hosts were prepared initially (VIB installs and VTEP VMkernels). So some of the things you want to be extra careful with during NSX host preparation will be…
- Properly adding the hosts to the vSphere Distributed Switch.
- NSX Host Preparation.
- If the VTEPs are provisioned from an IP Pool then make sure you have available addresses in the corresponding VTEP IP Pool.
Next, let’s talk about VSAN. You will simply need to review the procedure from VMware associated with scaling a VSAN cluster. You will likely have the new hosts placed into Maintenance Mode initially and then move them into the cluster. I like to use the “one at a time” approach versus throwing multiple servers in at once. That way if issues arise it makes troubleshooting easier. I also prefer adding my disks manually versus automatically. That way I have more control over the procedure versus having automatic simply do everything for me. There are pros and cons to both options so weigh the automatic vs. manual options beforehand.
You also have to figure out whether you are planning to scale up or scale out and which makes more sense. Cost will have a major influence here. Here is a great VMware Blog article from Pete Koehler…Options in Scalability with vSAN.
I like to design my VSAN nodes with scale up flexibility. If I need memory for my VSAN nodes I simply place each node into Maintenance Mode one at a time, service the node and bring it back online. Same thing applies to local storage resources. A majority of the 2U servers from various vendors (HPE, Dell, Cisco, etc.) support up to 24 SFF disks per node. THAT IS A LOT OF POTENTIAL STORAGE CAPACITY! So when you plan the VSAN nodes try and build flexibility to scale up (add local resources) and then scale out (add a node later). Some customers want everything MAXED OUT immediately and that is okay. They may not have the budget to do so and that is okay. When the customer asks about scaling their environment your answer will be simple….add another node and provide them the cost associated with it.
Important Note
One thing you want to remember to do in an environment designed this way is add the PSC and vCenter appliances to the list of exclusions in NSX. You do NOT want DFW policies applying to these VMs especially when you set DENY to the default “any any” rule. You will literally paint your PSC and vCenter appliances out of the equation and need to use a REST API to get yourself out of that jam. So do not forget to do that! I would need to do this in the mid-size environment above because my management VMs operate within the NSX transport zone boundary.
So that covers some of the basics design principles for a mid-sized VMware VSAN & NSX environment.
Designing for a Large Scale Deployment
This is a fun one that I enjoyed thoroughly. I’m going to enjoy doing it again with my second customer that I mentioned above who is starting with a fresh deployment. This is a much larger organization with many, many virtual workloads. This is where I like to design with a “pod” type of approach. Create building blocks. In some data centers that I have been in the PODs were identified as a specific number of physical racks. I have also seen instances where PODs were the logical layout of a cluster spanned across multiple racks. So there are different perspectives depending on how your customer identifies a POD.
Starting things off, the hardware resources (CPU, memory, disk and network) are stretched across racks and racks of equipment. In this situation we are defining PODs from a “physical” perspective. My customer defines the physical PODs as six (6) total racks…four (4) for compute and two (2) for networking.
What will the vSphere design look like after designing my physical and logical PODs? The vSphere environment is going to form my logical PODs…aka CLUSTERS! A separate cluster for compute, edge and management as you see in the graphic below.
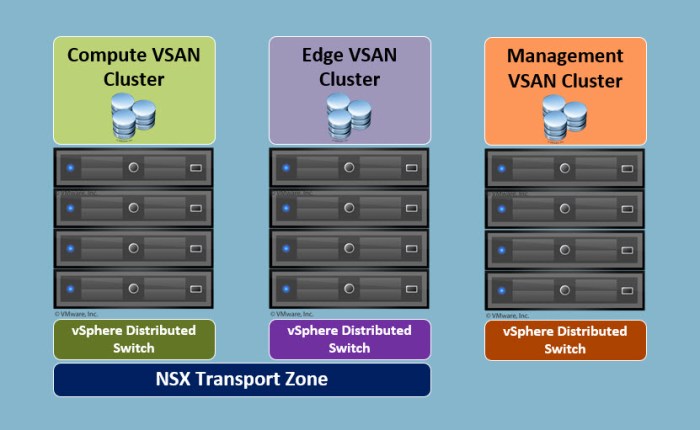
So again, this is a starting point for what this would look like at a minimum. A large scale deployment will likely involve clusters with a larger number of nodes per cluster. Easily double digit number of nodes in each. This is the type of environment where you want to be very well aware of your maximums for vSphere, VSAN and NSX. Bottom line is knowing where your “ceiling” is and the impact it will have moving forward.
NOTE: The ESXi hosts in the Management Cluster above will not require VXLAN provisioning which is why it is not part of the NSX Transport Zone. In a “collapsed” design found in the mid-sized infrastructure it will be necessary to prepare that cluster for VXLAN because you will be running the NSX edge appliances in the same cluster.
The diagram above is a logical representation for what it would look like in vSphere. How would I divide this up on a rack-to-rack basis in the physical data center?
This specific customer has a total of six (6) racks; two (2) of them are dedicated for network core route/switch. I did not not illustrate the network racks below but imagine they are there. I want to focus on the racks being where NSX and VSAN resources are located.
The remaining four (4) racks are entirely used for compute; each with redundant ToR switching. Being that this is a larger environment I am going to throw a little curveball here and double the number of compute VSAN nodes for the “logical cluster / rack” diagram for the sole purpose of showing you the impact it would have on the clusters in vSphere which I will get to in a minute.
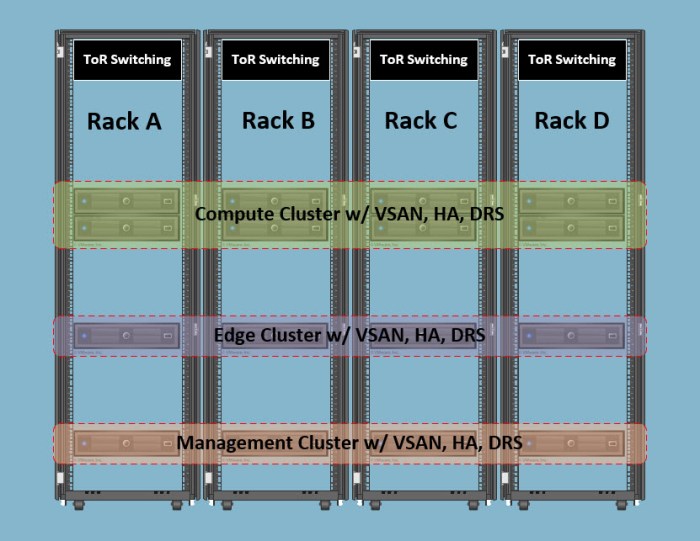
As you can see in the illustration above my clusters are spread EVENLY between each of the racks.
- One (1) management node per rack.
- One (1) edge node per rack.
- Two (2) compute nodes per rack.
This design provides a great degree of high availability and I avoid dedicating racks for specific workloads. Could I have done that? Sure. But I would be introducing unnecessary risk to availability in my overall design. There is also available rack space to expand each cluster. Assume everything becomes maximized the customer will need to deploy a new physical POD (6 new racks). Therefore, from a POD (rack) perspective they have the flexibility to scale up before they need to scale out.
Now let’s assume one rack fails in the POD above.
- What type of impact would this have on the three (3) VSAN clusters?
- How would I structure the VSAN policies?
- What type of impact would this have on HA design?
Let’s start with the Compute Cluster since that is a bit different now being that we starting with eight (8) nodes instead of four (4). If the requirement is stating that we need to design a solution based on “rack failure” then this means I need to design this cluster for a two (2) node failure. So for my HA design I simply choose the Percentage option for my Admission Control Policy and set this to 25% for CPU and memory.
I also have flexibility with my storage policies where I can design policies that accommodate both 1 and 2 node failures. I’m likely going to use the two node failure option in my policies because again…the design requirement is to factor in a single rack failure which would impact 2 nodes for this cluster. I also will have the flexibility to create performance based policies (RAID1) and capacity based policies (RAID5/RAID6 Erasure Coding where both can sustain a 2-node failure.
The Edge Cluster and the Management cluster are 100% identical. So they will utilize the same HA design and VSAN policies. The HA design for each cluster will utilize the Percentage option for my Admission Control Policy (25% for both CPU and memory).
The number failures to tolerate in my VSAN storage policies will be 1 at all times because of the number of nodes. I will be able to use the default RAID1 (performance) policy option as well as the RAID5/RAID6 (capacity) policy option but I will won’t be able to use the “2 node failure” option until I add more nodes to those clusters. Each cluster will need a minimum of two (2) more nodes (total of 6) in order to utilize the RAID5/RAID6 Erasure Coding option for two node failures.
So as the environment grows and the clusters scale I will gain more flexibility. I will have more flexibility initially in the Compute cluster simply because I have more nodes and this is likely where I want my flexibility to be anyway when I start constructing this environment because it is running the production workloads.
10GbE Networking and Mixed MTU Sizes
The 10GbE networking will play a major role for obvious reasons here. After all, it will be a requirement. For the mid-size environment, each of the nodes has a single dual-port 10GbE network adapter. There may be redundant ports but the card itself is a single point of failure (SPOF). So make that known before going forward and come up with a procedure to deal with the issue should an outage occur from an adapter failure.
The single 10GbE card with redundant ports will have an significant impact on my vSphere Distributed Switch (vDS) design. In this situation I plan on using NIOC to manage bandwidth consumption across the physical network uplinks. The other issue that I will encounter here will be dealing with MTU sizes. NSX will require a 1600 MTU size whereas VSAN will recommend a 9000 MTU size for optimal performance. A majority of ToR switches support a “global MTU size” versus a per port or per VLAN basis. So that will create a potential problem and MTU mismatch.
If there is no other way around it and I must use a switch technology that only supports setting MTU sizes at the global level…go with the HIGHER of the two. In this case I would set the MTU size to 9000 on the switches.
Also, take a good look at the core switching environment. If the customer is utilizing a core switch technology such as Cisco 4500, 6500 or Nexus 7K then you are in a good position as these switches support different MTU sizes on a per port/per VLAN basis. Tis is much more flexible plus it will increase performance and stability for both VSAN and NSX.
The best way to plan for this is plan ahead. If new equipment is ordered for a project that will involve an HCI and NSX implementation be very thorough with double and triple checking that bill of materials. If the customer plans on using “existing” equipment then you definitely want to conduct a very thorough discovery of the existing network. If you are not a networking guy then get your networking team involved and assist them throughout the process.
In a large scale environment I would make sure each of the nodes have two (2) dual port 10GbE network adapters at a minimum. This would enable me to design another level of redundancy and availability for both VSAN and NSX. I would dedicate one port on each adapter for NSX and the other for VSAN and completely separate them.
I would design a vSphere solution that would incorporate a separate vDS for VSAN and NSX. This design would enable me to set different MTU sizes on each vDS. I would set the 9000 MTU on my VSAN vDS and 1600 on my NSX vDS. Perfect! Do I need to create a separate vDS? No but from a logical point of view it would make sense.
If there is a budget for the additional network equipment I would design the entire VSAN network as a separate fabric. Logically and physically isolated from everything else. This would mean two (2) TOR switches for NSX network connectivity and two (2) TOR switches for VSAN storage connectivity. This would align my vDS design with my physical network design.
Conclusion
There are certainly many ways of tackling this type of design. Sometimes you may feel tempted to throw everything into one big bucket of resources and roll with it. While it may be possible and perhaps makes sense on the sense it may not be feasible. Always design based on project/business requirements first and then fill in gaps with “best practices” later.
My goal here is to share my experiences with you and provide you with a perspective that you may not have come across.
Useful Links
I provided quite a few links above but here are a few others that you should take a look at when designing VSAN and NSX.
NSX Reference Design Version 3.0 (PDF)
VMware Virtual SAN & VMware NSX Compatibility by Rawlinson Rivera
NSX-v: Design Deep Dive by Rene van den Bedem (VCDX133)
VMware Virtual SAN Design & Sizing Guide (now featuring VSAN 6.6)
HCI Automated Deployment & Configuration: vSphere, vSAN, NSX, VIO…the DevOps Way (Punching Clouds)
BE SOCIALABLE…PLEASE SHARE 🙂

question from your design i was looking same design from your above design logical PODs…aka CLUSTERS! A separate cluster for compute, edge and management
only question i have is i have two dell r630 server with 4×500 and 4x 4tb hard drive but one NUC with one TB ssd
Question: can i put compute and edge on both vsan cluster and management on NUC without creating Vsan on nuc. or i have to create vsan on NUC
LikeLike